Large Language Model Notes: Attention and Transformer
Eventually, my journey through neural networks has brought me to a point where I feel equipped with enough foundational knowledge to delve into the attention mechanism and transformer models in deep learning. I can’t help but start this post to record what I’ve learned so far, even as I continue exploring and deepening my understanding of these two intriguing topics.
Look Back Where I Started
Since this is a big milestone for me where I feel confident in understanding the two advanced topics, I want to take a moment to reflect on how I got here.
The first time I encountered the term “attention mechanism” and “transformer” was when chatGPT was released by OpenAI in November 2022. It caught everyone’s attention, because it was a breakthrough in NLP and demonstrated impressive capabilities in generating human-like texts and responses. Particularly, it aroused my great interest and make me wonder how it worked behind the chat box. At that time, I have no idea about the terms of “Generative Pre-trained Transformer” from the name chatGPT itself, how it is related to the attention mechanism, and what the famous “Attention is All You Need” paper is about.
I knew it wouldn’t be easy to understand all the related techniques in depth — especially for someone like me who had no prior background in NLP or deep learning — but I’ve always had a strong curiosity to dig into the mathematical details until I feel satisfied. About two years later, at the beginning of 2025, I finally decided to take on the challenge and start this learning journey.
My main approach has been to start from the basics of neural networks and follow the historical path of deep learning advancements, learning key techniques step by step - from (Neural Network Basics and Backpropagation, to Convolutional Neural Networks, Recurrent Neural Networks, and NLP - Word2Vec Embedding), until I naturally reached the attention mechanism and transformer models.
Now here I am.
From RNN to Attention
In my previous post on Recurrent Neural Networks and BPTT, I had this question:
"How did the development of RNNs lead to attention mechanisms, Transformers, GPT, and modern LLMs?"
After a few weeks of learning with various resources, I gradually formed a general picture of the evolution from RNNs to attention mechanisms, and further to Transformer architectures.
- RNNs were designed to handle sequential data as early as the 1980s. Instead of treating each input independently, they maintain a hidden state that captures information about previous inputs. However, RNNs suffer from the vanishing gradient problem, making it difficult to learn long-range dependencies.
- To mitigate this, LSTM and GRU architectures were introduced in the late 1990s and early 2010s. They handle longer-term dependencies better but remain inherently sequential, limiting parallelization during training.
- With the rise of tasks like machine translation, the sequence-to-sequence (seq2seq) model based on RNNs was proposed. It enabled end-to-end learning from input to output but still struggled with long sequences — the single context vector became a bottleneck, forcing the entire meaning of a sentence into one fixed-size vector.
-
To address this, the attention mechanism was introduced in seq2seq models. It allowed the model to dynamically attend to different parts of the input sequence while generating each output token, instead of relying on a single context vector. This greatly improved performance on translation and similar tasks.
However, these attention-based models still depended on RNNs, meaning they couldn’t fully escape sequential processing.
- Then in 2017, the Transformer architecture arrived with the landmark paper “Attention Is All You Need.” This was the revolutionary leap — attention without recurrence.
The Attention Mechanism
I find the Stanford CS231N Lecture 8 on Attention Mechanism and Transformers very helpful to understand the attention mechanism conceptually and how it is developed from RNNs.
Attention in Seq2Seq RNNs
This diagram below illustrates the attention mechanism initially introduced in the seq2seq model with RNNs to address the single context vector bottleneck:
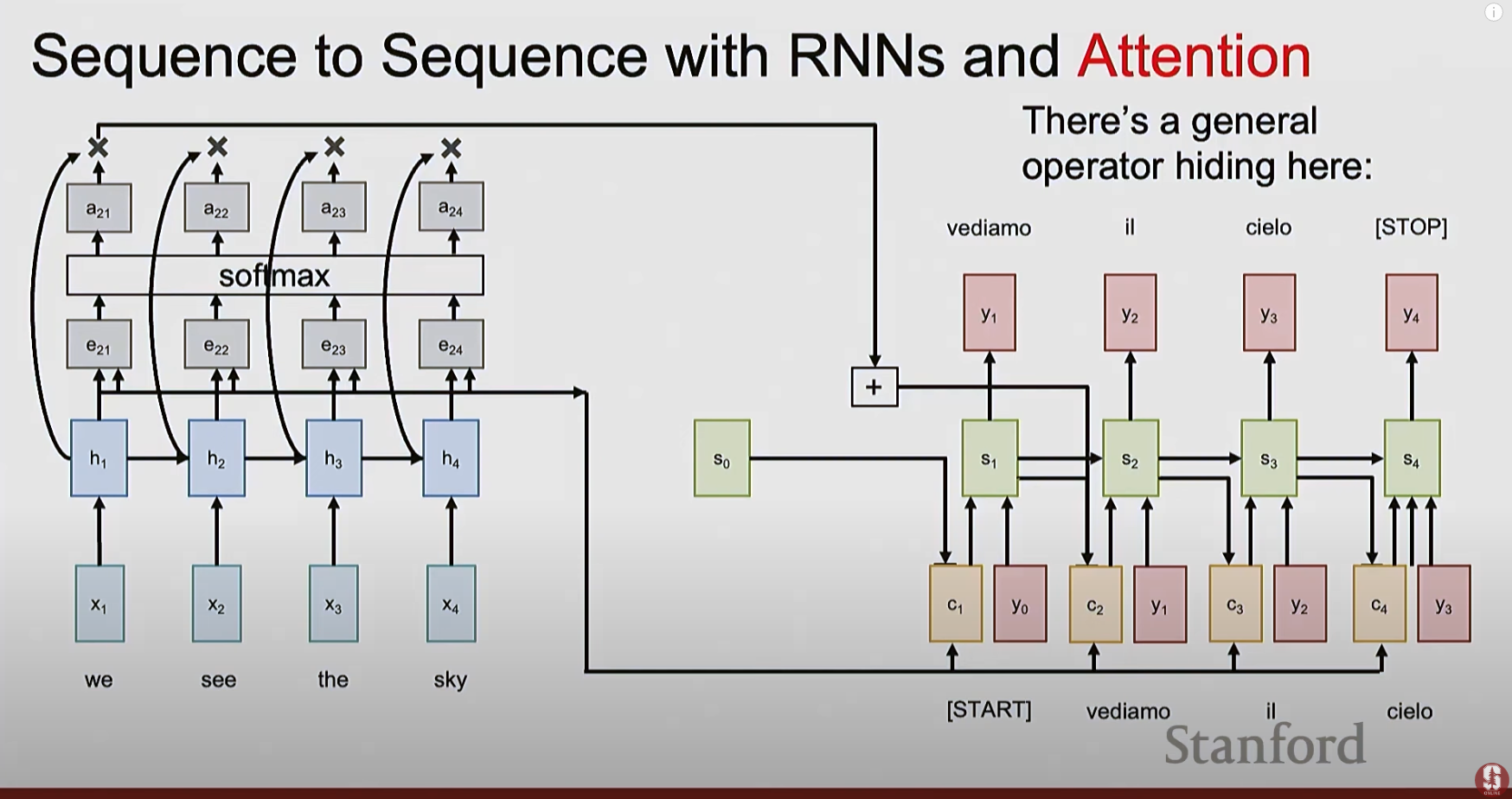
- Now each step in the decoder can attend to different parts of the input sequence by introducing the context vector (c_t).
- The context vector (c_t) is computed as a weighted sum of the encoder hidden states (h_i).
- The weights (alpha_{t,i}) are the (scalar) alignment scores that are computed by applying a “linear layer” to the concatenation of one of the decoder hidden states and the encoder hidden states, followed by a softmax function to normalize the alignment scores to get the attention weights.
- The “linear layer” can be implemented in various ways, such as using the Bahdanau attention (additive), Luong attention, or dot-product attention (multiplicative).
General Attention Mechanism
Then the attention mechanism turns out to be very powerful computational primitive in its own right, and can be used without RNNs at all. It is a general operator that takes in 3 set of vectors: queries (Q), keys (K), and values (V), and computes a weighted sum of the values, where the weights are determined by the similarity between the queries and keys. Below formula is using the scaled dot-product attention:
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]- The inputs can be one set of vectors - self-attention, or two sets of vectors - cross-attention.
- The queries, keys, and values can be obtained by projecting the input vectors using learnable weight matrices.
Below are the different types of attention layers I’ve captured from the lecture:
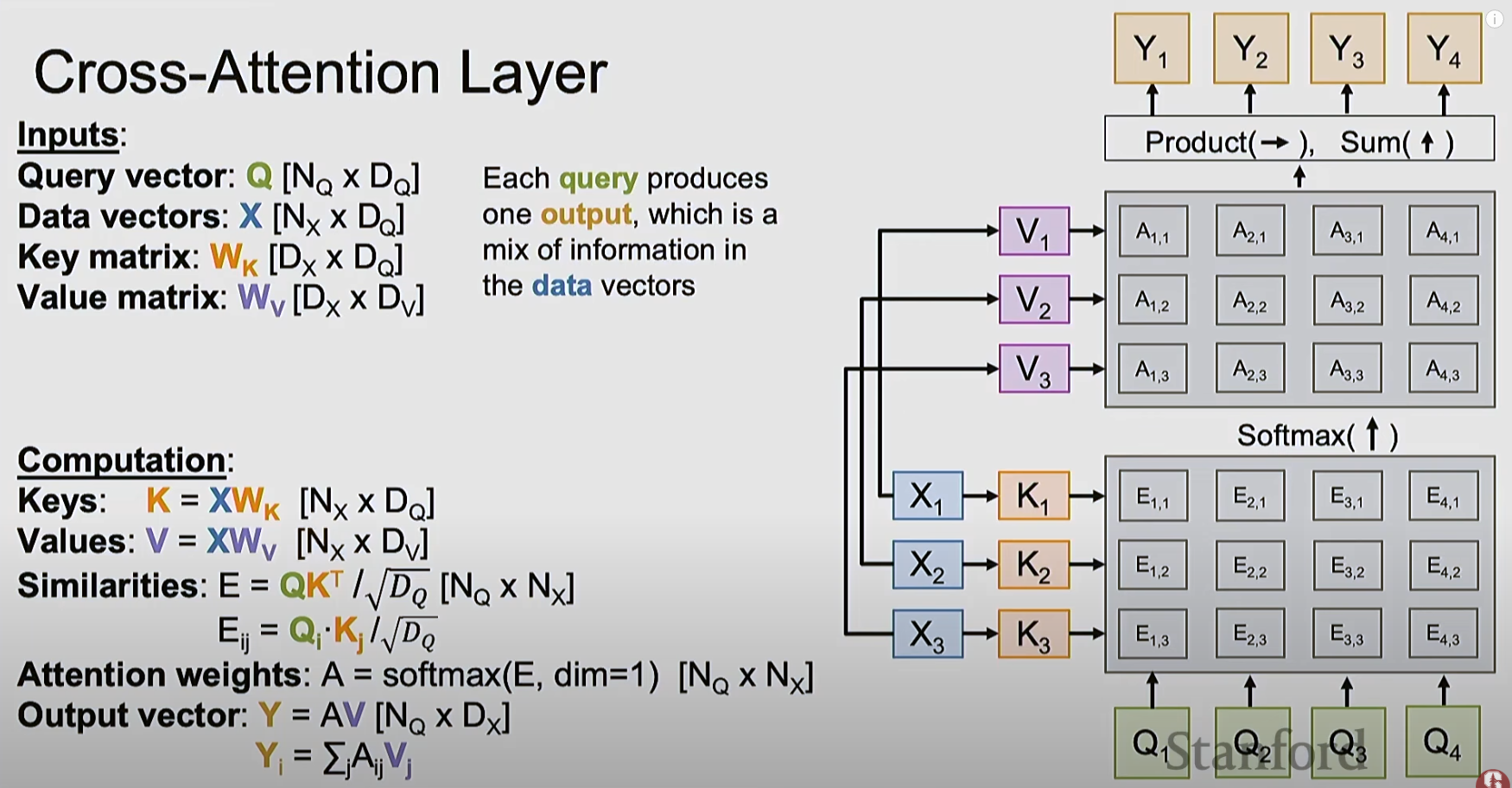
- This is called cross-attention, where it has two sets of inputs vectors - one is the query vectors, and the other is the data vectors which are used to project to keys and values.
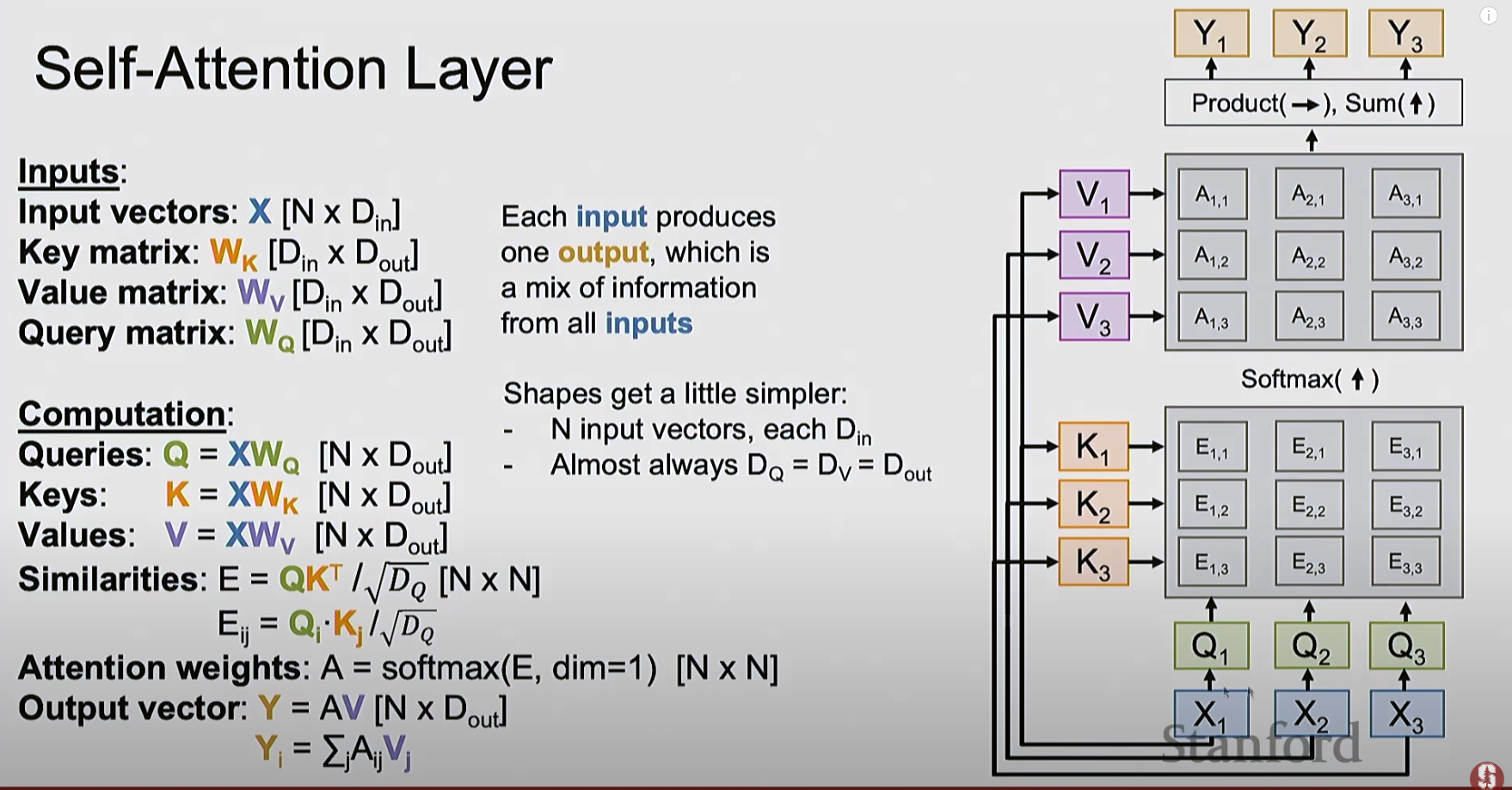
- This is called self-attention, where it has only one set of inputs vectors, projecting to 3 different things - queries, keys, and values.

- This is called masked self-attention, where it is the same as self attention, except the mask ensures that the model can only attend to previous tokens and not future ones.

- This is called multi-headed self-attention, where multiple attention heads can be run in parallel, allowing the model to learn different types of relationships simultaneously.
Transformer Architecture
Now, I can read the original paper “Attention is All You Need”, much easier than the first attempt a few years ago. The main breakthrough of the Transformer architecture is that it relies solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Besides, there are also some other key components in the Transformer architecture, taking important roles. Put them together comes the whole picture (image is referenced from the paper):
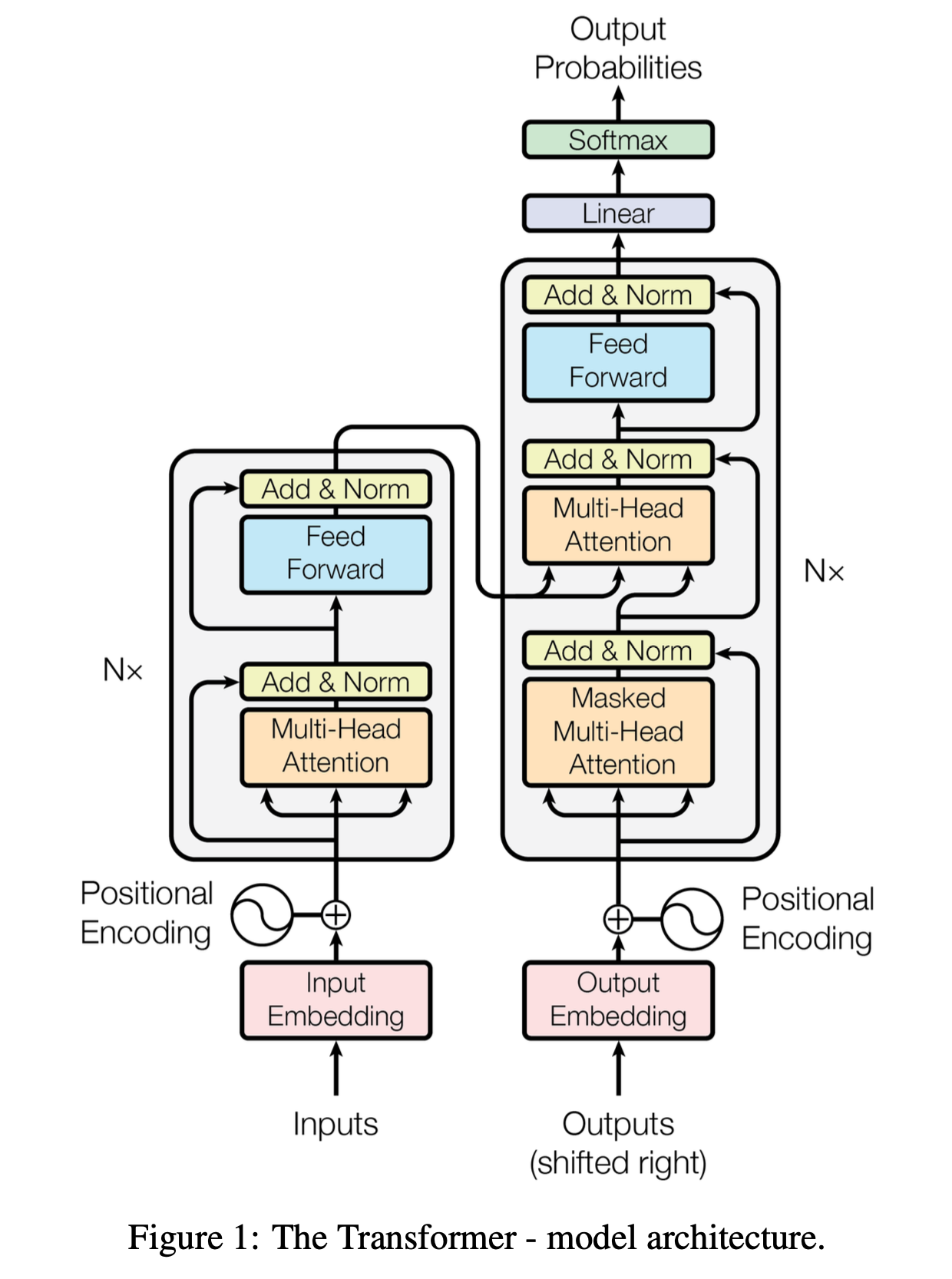
- The original Transformer model consists of an encoder and a decoder, each composed of multiple identical layers.
- Each encoder layer has two sub-layers: a multi-headed self-attention component and a fully connected feed-forward network.
- Each decoder layer has three sub-layers: a masked multi-headed self-attention component, a multi-headed cross-attention component, followed by a fully connected feed-forward network.
- Residual connections and layer normalization are applied after each sub-layer to stabilize training.
- Positional encoding is added to input embeddings for both the encoder and decoder to provide information about the position of tokens in the sequence, since the recurrent structure with the natural sequence order is removed completely.
- The word embeddings are part of the transformer model itself, that are learned during the training process. This means there isn’t a pre-existing, separate word embedding table (like Word2Vec or GloVe) that the model starts with. Instead, the embedding vectors for every word in the vocabulary are parameters of the Transformer model and are learned from scratch simultaneously with the rest of the model’s weights during the training process.
-
For a sequence of n tokens input, each head in the multi-headed attention layer products n output vectors - one per token. Then, these outputs from all heads are concatenated along the same token positions, and projected to produce the final n output vectors of the multi-headed attention layer. Mathematically, this can be expressed as:
\[\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h)W^O\] \[\text{head}_i = \text{Attention}(XW_i^Q, XW_i^K, XW_i^V)\]where, $X$ is the input sequence, and $W_i^Q$, $W_i^K$, $W_i^V$, $W^O$ are learnable weight matrices.
📝 Notes
If the transformer is used to predict the next token given an input sequence of n tokens (like in GPT models),
During training, after going through all layers, we get n contextual enriched embeddings corresponding to the n input tokens. Each embedding \(E_i\) will be individually passed through a linear layer followed by a softmax function:
\[P(w_{i+1}|w_1, w_2, \ldots, w_i) = \text{softmax}(E_i W^P + b^P)\]which gives n probability distributions of next token for each input token.
During inference, only the last token’s probability distribution is used to generate the next predicted token. The generated token is then appended to the input sequence for the next prediction.
Learning Resources
I’m deeply grateful for all the excellent free learning resources available online. Here are the ones I find particularly valuable in my learning of this topic:
- Attention is All You Need (Vaswani et al., 2017)
- Visualizing transformers and attention - Grant Sanderson
- Stanford CS224N: Lecture 7 - Attention, Final Projects and LLM Intro
- Stanford CS231N | Lecture 8: Attention Mechanism and Transformers
- Stanford CS25: V2 I Introduction to Transformers w/ Andrej Karpathy
Conclusion and Next Steps
I’m glad to have built a basic yet foundational understanding of the attention mechanism and transformer architecture. Though I’ve only scratched the surface of these complex topics, this marks a very important first step — one that gives me the confidence to keep exploring them in greater depth and gradually move into more advanced areas of modern large language models (LLMs).
So far, my learning has focused mostly on theory — reading papers, watching lectures, and digesting concepts. Next, I plan to get hands-on: to implement and train a small transformer model myself (if possible, or at least let me try). I believe this practical hands-on experience can help solidify my understanding of the transformer architecture.